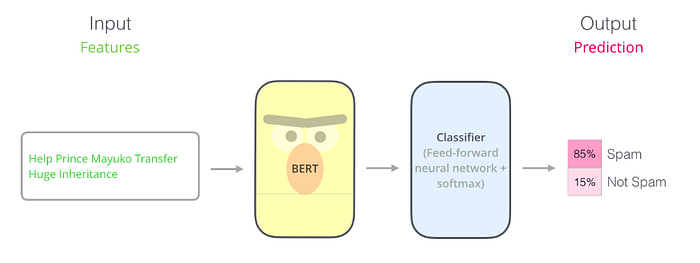
BERT Text Classification using Keras

The BERT (Bidirectional Encoder Representations from Transformers) model was proposed in BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. It’s a bidirectional transformer pre-trained using a combination of masked language modeling objective and next sentence prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
The unsupervised tasks like next sentence prediction on which BERT is trained to allow us to use a pre-trained BERT model by fine-tuning the same on downstream specific tasks such as sentiment classification, intent detection, question answering, and more.
Dataset Preparation
- Get the spam/ham classification dataset from Kaggle
- Clean the dataset (Follow the previous blog for understanding how to preprocess the NLP Dataset)
- Read the dataset
- We have un-necessary columns like ‘Unnamed: 2’, Let’s remove them and also, Let’s rename the column name ‘v1’ as ‘label’ and ‘v2’ as ‘text’.
- Now, Let’s clean the dataset and analyze the dataset
- Now, we have a clean dataset that we can feed to our BERT model.
Setting up a pre-trained BERT model for fine-tuning:
- Load the BERT tokenizer and the suitable BERT model.
from transformers import *
from transformers import BertTokenizer, TFBertModel, BertConfigbert_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")bert_model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased',num_labels=num_classes)
- Google Research recently open-sourced the tensorflow implementation of BERT and also released the following pre-trained models:
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parametersBERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Multilingual Case: 104 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
- All texts will be converted to lowercase and tokenized by the tokenizer and the tokenizer also takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
- Other tasks dependent variations of BERT models are:
- For Classification task, let’s use TFBertForSequenceClassification and bert-base-uncased.
BERT Tokenizer:
- BERT-Base, uncased uses a vocabulary of 30,522 words. The processes of tokenization involve splitting the input text into a list of tokens that are available in the vocabulary. In order to deal with the words not available in the vocabulary, BERT uses a technique called BPE based WordPiece tokenization. In this approach, an out of vocabulary word is progressively split into subwords and the word is then represented by a group of subwords. Since the subwords are part of the vocabulary, we have learned representations a context for these subwords and the context of the word is simply the combination of the context of the subwords.
- The tokens are either words or subwords. Here for instance, “calculates” wasn’t in the model vocabulary, so it’s been split into “calculate” and “##s”. To indicate those tokens are not separate words but parts of the same word, a double-hash prefix is added for “s”.
Parameters of TFBertForSequenceClassification model:
- input_ids: The input ids are often the only required parameters to be passed to the model as input. They are token indices, numerical representations of tokens building the sequences that will be used as input by the model. This can be obtained by the BERT Tokenizer.
- input_ids (
Numpy arrayortf.Tensorof shape(batch_size, sequence_length)) - Indices of input sequence tokens in the vocabulary.
batch_size :Number of examples or sentences batchsequence_length :A number of tokens in a sentence.
2. attention_mask (Numpy array or tf.Tensor of shape (batch_size, sequence_length)) –
- Mask to avoid performing attention on padding token indices. Mask values selected in
[0, 1]: 1 for tokens that are not masked, 0 for tokens that are marked (0 if the token is added by padding). - This argument indicates to the model which tokens should be attended to, and which should not.
- If we have 2 sentences and the sequence length of one sentence is 8 and another one is 10, then we need to make them of equal length and for that, padding is required. To distinguish between the padded and nonpadded input attention mask is used.
3. labels (tf.Tensor of shape (batch_size,), optional) – Labels for computing the sequence classification/regression loss.
- Indices should be in
[0, ..., num_classes- 1]. Ifnum_classes == 1a regression loss is computed (Mean-Square loss), Ifnum_classes > 1a classification loss is computed (Cross-Entropy). - These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding the sentence to the tokenizer.
- The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly.
- Decoding
- Special tokens (classifier
[CLS]and separator[SEP]) and [PAD] are added by the tokenizer.
Feel free to read about other parameters :)
Fine-tuning the pre-trained BERT model:
- BERT (Bidirectional Encoder Representations from Transformers) is a big neural network architecture, with a huge number of parameters, that can range from 100 million to over 300 million. So, training a BERT model from scratch on a small dataset would result in overfitting.
- So, it is better to use a pre-trained BERT model that was trained on a huge dataset, as a starting point. We can then further train the model on our relatively smaller dataset and this process is known as model fine-tuning.
- Let’s prepare the input data for the BERT Model, which contains
- Encoding of the labels
- Encoding of the text data using BERT Tokenizer and obtaining the input_ids and attentions masks to feed into the model.
- Save the data into pickle files (so that we don’t have to calculate the encodings, again and again, we can directly load the pickle files)
- Loading the pickle files
- Spitting into train and validation set
- Setting up the loss, metric, and the optimizer.
- Training the model
Encoding of the labels
- Convert ‘ham’ to 0 and ‘spam’ to 1 and save it into a new column ‘gt’ (ground truth).
- Sentences contain the entire text data and labels contain all the corresponding labels.
Encoding of the text data using BERT Tokenizer and obtaining the input_ids and attentions masks to feed into the model.
- Load the sentences into the BERT Tokenizer.
- BERT Tokenizer returns a dictionary from which we can get the input ds and the attention masks.
- Convert all the encoding to NumPy arrays.
- Arguments of BERT Tokenizer:
- text (
str,List[str],List[List[str]]) – The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences).
2. add_special_tokens (bool, optional, defaults to True) – Whether or not to encode the sequences with the special tokens relative to their model.
3. max_length (int, optional) — Controls the maximum length to use by one of the truncation/padding parameters. (max_length≤512)
4. pad_to_max_length (bool, optional, defaults to True) – Whether or not to pad the sequences to the maximum length.
5. return_attention_mask (bool, optional) –
Whether to return the attention mask. If left to the default will return the attention mask according to the specific tokenizer’s default, defined by the return_outputs attribute.
Saving and loading the data into the pickle files:
Spitting into train and validation set
- Split the dataset (input_ids,attention_masks and labels) into train and Val sets (80–20), set the test_size=0.2 i.e 20%.
- train_test_split: Split arrays or matrices into the random train and test subsets
Setting up the loss, metric and the optimizer
- A callback is an object that can perform actions at various stages of training (e.g. at the start or end of an epoch, before or after a single batch, etc).
- Callbacks are used to:
- Write TensorBoard logs after every batch of training to monitor your metrics
2. Periodically save your model to disk
3. Do early stopping
4. Get a view on internal states and statistics of a model during training
5. …and more
- Here, I am saving the model based on min val loss, setting monitor=’val_loss’,mode=’min’ in ModelCheckpoint callbacks.
Training the model
- The training will take a lot of time depending on the maximum length used in the BERT Tokenizer, batch size, and the number of epochs.
- We can also use DistilBERT, in smaller datasets for faster training.
Evaluating the performance of the model
- How do we evaluate our model and how to we calculate the labels for our unknown data?
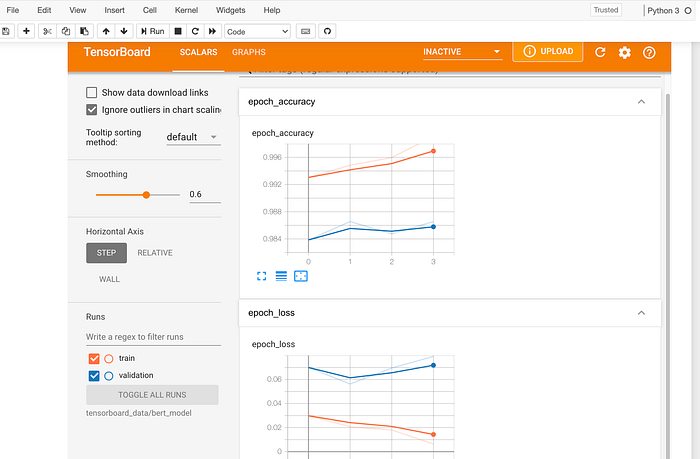
Training -testing curve using Tensorboard
- The above line executes a visualization from which we can analyze the training and validation curves and tune the hyper-parameters accordingly.
- We can also visualize the tensorboard from the terminal, in case there is an issue in the notebook. Follow this
- Feel free to add more parameters to the callbacks and visualize the curves, for eg. F1 Score.
- In this case, BERT is overfitting on the dataset, which usually happens in smaller datasets.
Calculating predictions, F1-score and the accuracy
- Load the saved model with the same parameters as used in the training.
model.predict gives the probability of the labels, Let's say we have 10 val_inp then dimensions of the preds will be (10,2)Then we apply argmax and obtain the predicted labels.pred_labels.shape -- (10,)eg. preds:array([[0.34,0.72],
[0.2,0.8]]) and so on.
this means that for 1st sample the prob. of the label 0 is 0.34 and prob. of 1 label is 0.72so we take the argmax in axis=1 and get the label of the maximum probabilitypred_labels:
[1,1....]
- To get the validation parameters, use
trained_model.evaluate([val_inp,val_mask],batch_size=32)That’s all 🤓
Happy Learning :)